
Project Part 1 requires you to complete an anytime, forward-searching, depth-bounded, utility-driven scheduler. The goal is to create schedules for a particular virtual country (your country), but the state of the world will impact the state of each country in at least one way.
The top level function is prototyped as
def my_country_scheduler (your_country_name,
resources_filename,
initial_state_filename,
output_schedule_filename,
num_output_schedules,
depth_bound,
frontier_max_size)
where most of the parameters are explained in section Input and Output, but the final two parameters are described in section The Search Strategy.
Input and Output
Each implementation will read the following information from excel spreadsheets
- names, weights, and factor definitions of resources (parameter resources_filename — see The State Quality of a Country). See an example at Example-Sample-Resources.xlsx
- the initial state of the world in terms resource amounts per country (parameter initial_state_filename) — this is where you also define the country labels, and you should identify the country label that corresponds to “self” (you). See an example initial world at Example-Initial-Countries.xlsx
A team can post to Piazza its code for translating input files to internal representation. Yes, that team has the opportunities for citation credit. This is the only code you can post to Piazza without prior permission.
Each implementation will write out an ordered list of num_output_schedules schedules to a file, output_schedule_filename, for each initial state problem. The format of output schedules is specified for you (see below).
The State Quality of a Country
The state quality of a country is determined by each team, though teams can share quality functions on Piazza and in-class in a form that is comprehensible to others, but not in the form of code. The country state quality function, whatever it is, must be substantively dependent on a country’s resources. The state quality function could be a weighted sum of resource factors as we discussed in project background, for example, and it could be normalized by the population resource, such as w_Ri * c_Ri * A_Ri / A_Population, where A_Ri is the amount of a resource, and c_Ri is a proportionality constant (e.g., 2 units food per person, 0.5 house per person). Or the quality function could be an ecological footprint that is normalized by the AvailableLand resource. State Quality could take some other form as well.
In any case, some kind of weighting of resources will likely be important. Your choice of State Quality should be informed by one or more sources of what are relevant measures of country health in the real world (though avoid getting into “the weeds“), and you can share these sources over Piazza or live in class.
Resources
The Resources used in defining states, computing state quality, and the like, must include resources with *
AvailableLand
Water
Population*
PopulationWaste
MetallicElements*
Timber*
Farm (Farm is obtained from AvailableLand and reduces the AvalilableLand amount)
FarmWaste
MetallicAlloys*
MetallicAlloysWaste*
Electronics*
ElectronicsWaste*
Housing*
HousingWaste*
Food (Food is enabled by the Farm resource, perhaps accompanied by Water)
FoodWaste
PotentialFossilEnergy (e.g., oil)
PotentialFossilEnergyUsable (e.g., oil that is extracted from land, can be exported)
PotentialFossilEnergyUsableWaste (e.g., waste as a result of the extraction process)
PotentialRenewableEnergy
PotentialRenewableEnergyUsable
PotentialRenewableEnergyUsableWaste
For the required (*) created resources, use these transformations (same as transformations at project background page) but only including required resources* above)
Housing Template (TRANSFORM ?C (INPUTS (Population 5) (MetallicElements 1) (Timber 5) (MetallicAlloys 3)) (OUTPUTS (Housing 1) (HousingWaste 1) (Population 5)))
Alloys Template
(TRANSFORM ?C (INPUTS (Population 1)
(MetallicElements 2))
(OUTPUTS (Population 1)
(MetallicAlloys 1)
(MetallicAlloysWaste 1)))
Electronics Template
(TRANSFORM ?C (INPUTS (Population 1)
(MetallicElements 3)
(MetallicAlloys 2))
(OUTPUTS (Population 1)
(Electronics 2)
(ElectronicsWaste 1)))
Each ?Ak refers to the amount of resource Rk that is required as an input to the transform. Each ?C(?Rk) is the amount of resource ?Rk that is possessed by country ?C. That is, country ?C must possess at least as much of resource ?Rk as required for the transform.
Including one or more other resources can get you additional points, particularly if you have sources to support, even vaguely, for your design of TRANSFORMations. Every resource that has an associated Waste resource, must be accompanied by that Waste resource in your state definition. FYI: Water is involved (in the real world) in virtually every transformation (e.g., https://www.patagonia.com/our-footprint/organic-cotton.html), and this inclusion of water would be an example of citing sources to support your transformation definitions.
The Format of a Schedule
A schedule is formatted as a sequence (list) of TRANSFORM and TRANSFER operations that are each fully grounded (i.e., all variables replaced by constants). For example,
[ (TRANSFORM ?C1 (INPUTS (Population 25)
(MetallicElements 5)
(Timber 25)
(MetallicAlloys 15))
(OUTPUTS (Housing 5)
(HousingWaste 5)
(Population 25)))
(TRANSFER ?C1 ?C2 ((Housing 3))
...
…..
though probably with ?C1 and ?C2 bound to particular countries, one of which is typically (but not necessarily) your team’s country. (An aside: allowing variables in a schedule that represent another country is often beneficial and allows for flexibility at schedule execution time, but I would ground all variables to constants in a schedule).
The first operator in the schedule will change the initial state into a second state with certainty, the second operator in the schedule will change the second state into a third state with certainty, etc. Thus, there are no uncertainties associated with the effects of operators. The state that precedes an operator’s application must satisfy the preconditions of that operator (i.e., the country that is executing a transform or transfer must have sufficient resources). A schedule in which each operator’s preconditions are satisfied just prior to the operator’s application is called a legal schedule.
The Undiscounted Reward to a Country of a Schedule
The reward of a schedule can be positive or negative, and is the difference between the state quality of the end state of the schedule for a country and the state quality of the start state for the same country.
A schedule can benefit or degrade countries to varying extents, so each country that participates in a schedule probably has a different reward for a given schedule.
Remember, you design how to implement state quality for a country as discussed above, but you must use the difference in quality as the undiscounted reward:
R(c_i, s_j) = Q_end(c_i, s_j) – Q_start(c_i, s_j) to a country c_i of a schedule s_j.
The Discounted Reward to a Country of a Schedule
Reward comes from the end state of a schedule but the farther the end state is into the future, the less it counts for a country (that’s our assumption anyways). If there are N time steps in a schedule, then the discounted expected reward for a country is
DR(c_i, s_j) = gamma^N * (Q_end(c_i, s_j) – Q_start(c_i, s_j)), where 0 <= gamma < 1.
For many other sequential decision problems (Chapter 17, Russell and Norvig; Chapter 9, Poole and Mackworth) each state in the sequence comes with some reward (positive or negative/penalty), and the utility of the sequence is the sum of discounted state rewards, but in our case, we assume that the reward comes at the end state only. Nonetheless, your system can (and probably will) compute the discounted end state quality for every partial schedule on the search frontier, which presumably would be used to organize the frontier as a priority queue (also see The Expected Utility of a Schedule). Each team will experiment with different values of gamma.
The Probability that a Schedule will Succeed
Even when there is no uncertainty associated with an operator’s effects when the operator is applied, and therefore no uncertainty associated with a legal schedule’s effects when the schedule is applied, there remains other sources of uncertainty in the schedule. Notably, other countries referenced in the schedule may not “go along” with the schedule in an attempt were made to “execute” it in the real world. You will use qualities for other countries, and rewards to them, as well as for your own country, to judge the likelihood that a schedule will be accepted by all parties.
Notably, if a schedule references a number of other countries, then the more that the schedule will benefit each of the referenced countries (i.e., in terms of discounted reward), then the chances that they will agree to the schedule increases — at least that is our assumption.
The probability that a country, c_i, will participate in a schedule, s_j, is computed by the logistic function where x corresponds to DR(c_i, s_j) and L = 1, and you can experiment with different values of x_0 and k (but use x_0 = 0 and k =1 as starting points). Think about, and report on, how different parameter settings might reflect biases in the real world (e.g., a reason for shifting x_0 might be to reflect opportunity costs — what other possibilities might await a patient country?).
Given the individual probabilities of each referenced country participating, P(c_i, s_j), the probability that a schedule will be accepted and succeed, P(s_j), could be computed in a number of ways (e.g., the min of the probabilities, reflecting the weakest link), but we’ll use the product of the probabilities of the individual P(c_i, s_j).
Note that the strategy for estimating a probability that a schedule is accepted (i.e., will be accepted by all parties to the schedule) and succeeds, does not come from statistics accumulated over data from the “real world” (to include game play) as we might think is ideal, but our method draws from an information theoretic tradition of estimating probabilities of “events” from the “descriptions” of those events. An assumption in this description-driven methodology is a bias that more “complicated” descriptions represent lower probability events. Its a quantification of Occam’s razor.
This is the one way (probably the only way given time constraints in Part 1) that your scheduler for your country will take into account the state qualities of other countries, as well as your own.
The Expected Utility to a Country of a Schedule
The probability that a schedule will be accepted and succeed (which takes into account other countries) multiplied by the discounted reward for your country (self) is the central factor in computing the expected utility of a schedule (s_j) for your country (self, c_i). But what is the cost to a country of producing a schedule that would ultimately fail? For simplicity, let the cost of the failure case be a negative constant, C. You choose C, with justification given, or if you are more ambitious, design a more general function to represent the failure cost.
EU(c_i, s_j) = (P(s_j) * DR(c_i, s_j)) + ((1-P(s_j)) * C), where c_i = self
Summarizing the Interdependence of Measures
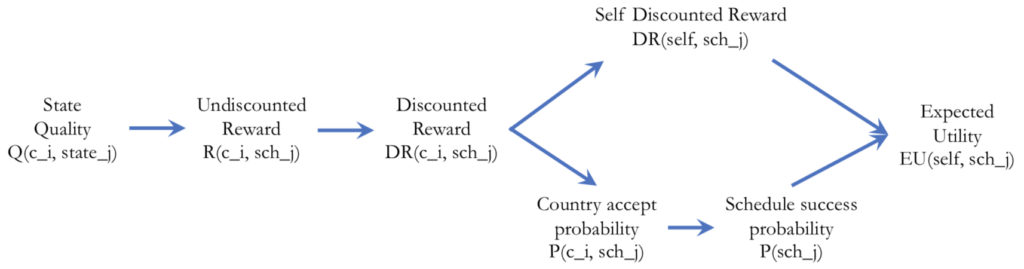
Inter-dependence between measures
The Search Strategy
Your search strategy is anytime, forward-searching, depth-bounded, first-order, utility-driven scheduler.
The search is country centric, and at least one country variable, ?c, in any final schedule should be bound to ‘self’. It well may be the case that your search implementation insists that every operator in a schedule has a country variable bound to self. Each team decides on this constraint.
By forward searching, each problem starts with an initial world state, and searches into the future. This is NOT a regression (or backward) search. Use the skeletal algorithms for generic search found in Poole and Mackworth or Russell and Norvig, which use an explicit frontier data structure (in your case, a priority queue). Your implementation cannot be recursive (there is no advantage in it, and you might inadvertently implement a depth first search, which would lose big points on this deliverable).
A utility-driven scheduler means that a utility measure organizes the priority queue that we are calling the frontier (as do Poole and Mackworth, and Russell and Norvig). Use EU(self, s_j’) to organize the search frontier, where s_j’ is a partial schedule on the frontier that is at depth less than depth-bound.
The depth-bound specifies a maximum depth to search (assuming the initial state is depth 0) — the maximum depth of nodes on the frontier. It also defines the depth that your implementation must search along every search path, except in a rare situation when a path cannot be advanced further (i.e., the generate successors function yields the empty set for a state on the frontier). Thus, you can’t just search to depth 1 by a single execution of the generate-successors function to the initial state). Importantly, for each state of each final schedule (path) that is found by your scheduler, the EU(self, s_j’) value of the partial schedule, s_j’, should accompany the schedule, which will also include the EU(self, s_j) of the entire schedule, s_j. Thus, schedules in the output file output_schedule_filename will be formatted like
[ (TRANSFORM self ...) EU: S_1 (TRANSFER self C2 ((Housing 3)) EU: S_2 ... (TRANSFORM self ...) EU: S_N
Our reason for printing out these intermediate values is to see whether frontier scores can get worse before they get better, as well as easily identifying an the best sub-schedule within the schedule that goes to depth bound.
Priority queue size will limit the size of the frontier and thus the extent of search, but you will choose what to place in the queue. Will you simply place the top scoring partial schedules found throughout search (even if they share almost all ancestors), or will you place schedules found through different paths to implement a search with greater ancestral diversity?
Finally, your anytime implementation will continue to search for schedules at depth-bound even after the first such schedule is found. When adapting the generic search algorithm in your intro texts, remember that these algorithms are goal based, and there are no goals per se in your implementation, or alternatively you will consider schedules at depth-bound as “goals”, and keeping track of the best schedule in terms of EU found so far will complete your anytime implementation. In terms of your final report, for each problem, you will report the EU scores in order that they were discovered, and create a scatter plot of these to see if better schedules tend to be discovered early, as we would hope in an anytime search.
See Part 1 Deliverables