Self-Assessed Performance Improves Statistical Fusion of Image Labels.
Frederick W. Bryan, Zhoubing Xu, Andrew J. Asman, Wade M. Allen, Daniel S. Reich, and Bennett A. Landman. “Self-Assessed Performance Improves Statistical Fusion of Image Labels.” Medical Physics. 2014 Mar;41(3):031903. PMC24593721†
Full Text: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3978333/
Abstract
Purpose: Expert manual labeling is the gold standard for image segmentation, but this process is difficult, time-consuming, and prone to inter-individual differences. While fully automated methods have successfully targeted many anatomies, automated methods have not yet been developed for numerous essential structures (e.g., the internal structure of the spinal cord as seen on magnetic resonance imaging). Collaborative labeling is a new paradigm that offers a robust alternative that may realize both the throughput of automation and the guidance of experts. Yet, distributing manual labeling expertise across individuals and sites introduces potential human factors concerns (e.g., training, software usability) and statistical considerations (e.g., fusion of information, assessment of confidence, bias) that must be further explored. During the labeling process, it is simple to ask raters to self-assess the confidence of their labels, but this is rarely done and has not been previously quantitatively studied. Herein, the authors explore the utility of self-assessment in relation to automated assessment of rater performance in the context of statistical fusion.
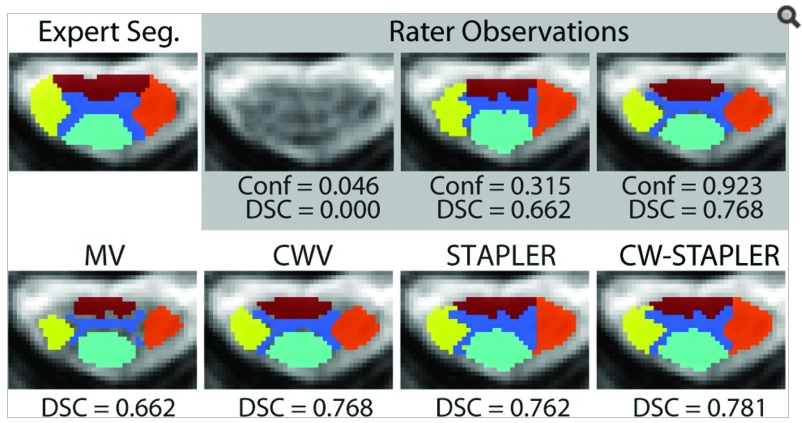
Methods: The authors conducted a study of 66 volumes manually labeled by 75 minimally trained human raters recruited from the university undergraduate population. Raters were given 15 min of training during which they were shown examples of correct segmentation, and the online segmentation tool was demonstrated. The volumes were labeled 2D slice-wise, and the slices were unordered. A self-assessed quality metric was produced by raters for each slice by marking a confidence bar superimposed on the slice. Volumes produced by both voting and statistical fusion algorithms were compared against a set of expert segmentations of the same volumes.
Results: Labels for 8825 distinct slices were obtained. Simple majority voting resulted in statistically poorer performance than voting weighted by self-assessed performance. Statistical fusion resulted in statistically indistinguishable performance from self-assessed weighted voting. The authors developed a new theoretical basis for using self-assessed performance in the framework of statistical fusion and demonstrated that the combined sources of information (both statistical assessment and self-assessment) yielded statistically significant improvement over the methods considered separately.
Conclusions: The authors present the first systematic characterization of self-assessed performance in manual labeling. The authors demonstrate that self-assessment and statistical fusion yield similar, but complementary, benefits for label fusion. Finally, the authors present a new theoretical basis for combining self-assessments with statistical label fusion.