Deep Learning Category
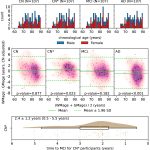
Brain age identification from diffusion MRI synergistically predicts neurodegenerative disease
Dec. 8, 2025—Chenyu Gao, Michael E Kim, Karthik Ramadass, Praitayini Kanakaraj, Aravind R Krishnan, Adam M Saunders, Nancy R Newlin, Ho Hin Lee, Qi Yang, Warren D Taylor, Brian D Boyd, Lori L Beason-Held, Susan M Resnick, Lisa L Barnes, David A Bennett, Marilyn S Albert, Katherine D Van Schaik, Derek B Archer, Timothy J Hohman, Angela...

Pitfalls of defacing whole-head MRI: re-identification risk with diffusion models and compromised research potential
Dec. 8, 2025—Chenyu Gao, Kaiwen Xu, Michael E Kim, Lianrui Zuo, Zhiyuan Li, Derek B Archer, Timothy J Hohman, Ann Zenobia Moore, Luigi Ferrucci, Lori L Beason-Held, Susan M Resnick, Christos Davatzikos, Jerry L Prince, Bennett A Landman. “Pitfalls of defacing whole-head MRI: re-identification risk with diffusion models and compromised research potential”. Computers in Biology and Medicine....

Multipath cycleGAN for harmonization of paired and unpaired low-dose lung computed tomography reconstruction kernels
Dec. 5, 2025—Aravind R Krishnan, Thomas Z Li, Lucas W Remedios, Michael E Kim, Chenyu Gao, Gaurav Rudravaram, Elyssa M McMaster, Adam M Saunders, Shunxing Bao, Kaiwen Xu, Lianrui Zuo, Kim L Sandler, Fabien Maldonado, Yuankai Huo, Bennett A Landman, Medical Physics, Volume 52, Issue 11, DOI: https://doi.org/10.1002/mp.70120 Abstract Background Reconstruction kernels in computed tomography (CT) introduce...
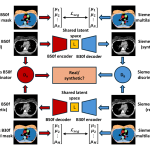
Anatomy-Guided Multi-Path CycleGAN for Lung CT Kernel Harmonization
Dec. 5, 2025—Aravind Krishnan, Thomas Li, Lucas Walker Remedios, Kaiwen Xu, Lianrui Zuo, Kim L Sandler, Fabien Maldonado, Bennett Allan Landman, MIDL 2025, Link to paper: https://openreview.net/pdf?id=w3p7GddsQ8 Abstract Accurate quantitative measurement in lung computed tomography (CT) imaging often re- lies on consistent kernel reconstruction across scanners and manufacturers. Harmonization can reduce measurement variability caused by heterogeneous...

DeepFixel: Crossing white matter fiber identification through spherical convolutional neural networks
Dec. 2, 2025—Adam M. Saunders, Lucas W. Remedios, Elyssa M. McMaster, Jongyeon Yoon, Gaurav Rudravaram, Adam Sadriddinov, Praitayini Kanakaraj, Bennett A. Landman, and Adam W. Anderson. DeepFixel: Crossing white matter fiber identification through spherical convolutional neural networks. Accepted to SPIE Medical Imaging: Clinical and Biomedical Imaging, February 2026. https://arxiv.org/abs/2511.03893 Abstract Diffusion-weighted magnetic resonance imaging allows for...
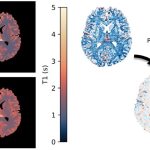
Comparison and calibration of MP2RAGE quantitative T1 values to multi-TI inversion recovery T1 values
Apr. 13, 2025—Adam M. Saunders, Michael E. Kim, Chenyu Gao, Lucas W. Remedios, Aravind R. Krishnan, Kurt G. Schilling, Kristin P. O’Grady, Seth A. Smith, and Bennett A. Landman. Comparison and calibration of MP2RAGE quantitative T1 values to multi-TI inversion recovery T1 values. Magnetic Resonance Imaging, 2025; 117:110322. https://doi.org/10.1016/j.mri.2025.110322. Abstract While typical qualitative T1-weighted magnetic resonance images...
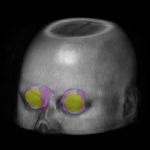
Super-resolution multi-contrast unbiased eye atlases with deep probabilistic refinement
Nov. 6, 2024—Ho Hin Lee, Adam M. Saunders, Michael E. Kim, Samuel W. Remedios, Lucas W. Remedios, Yucheng Tang, Qi Yang, Xin Yu, Shunxing Bao, Chloe Cho, Louise A. Mawn, Tonia S. Rex, Kevin L. Schey, Blake E. Dewey, Jeffrey M. Spraggins, Jerry L. Prince, Yuankai Huo, Bennett A. Landman, Super-resolution multi-contrast unbiased eye atlases with deep...
Field-of-view extension for brain diffusion MRI via deep generative models
Jul. 1, 2024—Chenyu Gao, Shunxing Bao, Michael E Kim, Nancy R Newlin, Praitayini Kanakaraj, Tianyuan Yao, Gaurav Rudravaram, Yuankai Huo, Daniel Moyer, Kurt Schilling, Walter A Kukull, Arthur W Toga, Derek B Archer, Timothy J Hohman, Bennett A Landman, Zhiyuan Li. “Field-of-view extension for brain diffusion MRI via deep generative models”. Journal of Medical Imaging 11 (4),...
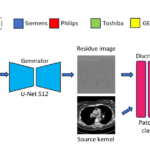
Lung CT harmonization of paired reconstruction kernel images using generative adversarial networks
Apr. 24, 2024—Aravind R. Krishnan, Kaiwen Xu, Thomas Li, Lucas W. Remedios, Kim L. Sandler, Fabien Maldonado, Bennett A. Landman. “Lung CT harmonization of paired reconstruction kernel images using generative adversarial networks.”Med Phys. 2024;1-14.https://doi.org/10.1002/mp.17028 Abstract Background The kernel used in CT image reconstruction is an important factor that determines the texture of the CT image. Consistency of reconstruction...
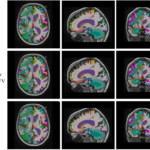
Enhancing Hierarchical Transformers for Whole Brain Segmentation with Intracranial Measurements Integration
Dec. 20, 2023—Xin Yu, Yucheng Tang, Qi Yang, Ho Hin Lee, Shunxing Bao, Yuankai Huo, and Bennett A. Landman. “Enhancing Hierarchical Transformers for Whole Brain Segmentation with Intracranial Measurements Integration.” SPIE Medical Imaging 2024 Full text: NIHMSID Abstract: Whole brain segmentation with magnetic resonance imaging (MRI) enables the non-invasive measurement of brain regions, including total intracranial volume (TICV) and...