Lucas W. Remedios, Sneha Lingam, Samuel W. Remedios, Riqiang Gao, Stephen W. Clark, Larry T. Davis, Bennett A. Landman. Technical Note: Comparison of Convolutional Neural Networks for Detecting Large Vessel Occlusion on Computed Tomography Angiography. Medical Physics, 2021
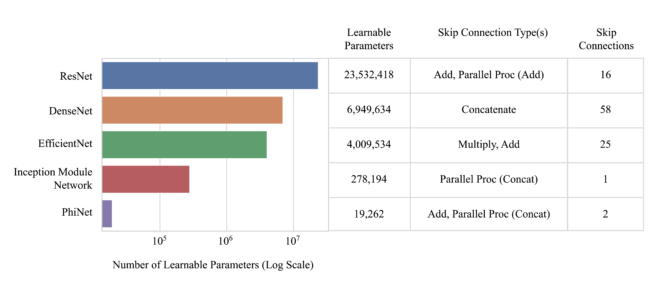
Purpose: Artificial intelligence diagnosis and triage of large vessel occlusion may quicken clinical response for a subset of time-sensitive acute ischemic stroke patients, improving outcomes. Differences in architectural elements within data-driven convolutional neural network (CNN) models impact performance. Foreknowledge of effective model architectural elements for domain-specific problems can narrow the search for candidate models and inform strategic model design and adaptation to optimize performance on available data. Here, we study CNN architectures with a range of learnable parameters and which span the inclusion of architectural elements, such as parallel processing branches and residual connections with varying methods of recombining residual information.Methods: We compare five CNNs: ResNet-50, DenseNet-121, EfficientNet-B0, PhiNet, and an Inception module-based network, on a computed tomography angiography large vessel occlusion detection task. The models were trained and preliminarily evaluated with 10-fold cross-validation on preprocessed scans (n = 240). An ablation study was performed on PhiNet due to superior cross-validated test performance across accuracy, precision, recall, specificity, and F1 score. The final evaluation of all models was performed on a withheld external validation set (n = 60) and these predictions were subsequently calibrated with sigmoid curves.Results: Uncalibrated results on the withheld external validation set show that DenseNet-121 had the best average performance on accuracy, precision, recall, specificity, and F1 score. After calibration DenseNet-121 maintained superior performance on all metrics except recall.Conclusions: The number of learnable parameters in our five models and best-ablated PhiNet directly related to cross-validated test performance—the smaller the model the better. However, this pattern did not hold when looking at generalization on the withheld external validation set. DenseNet-121 generalized the best; we posit this was due to its heavy use of residual connections utilizing concatenation, which causes feature maps from earlier layers to be used deeper in the network, while aiding in gradient flow and regularization.
A comparison of the number of learnable parameters and the types and number of skip connections in our five models. Note that the skip connections type column lists operations which show how residual information is reintegrated when the skip / residual connection or parallel processing branch rejoins the network.