Label efficient segmentation of single slice thigh CT with two-stage pseudo labels
Qi Yang, Xin Yu, Ho Hin Lee, Yucheng Tang, Shunxing Bao,Kristofer S. Gravenstein, Ann Zenobia Moore, Sokratis Makrogiannis, Luigi Ferrucci, and Bennett A. Landman. “Label efficient segmentation of single slice thigh CT with two-stage pseudo labels” Journal of Medical Imaging, 2022
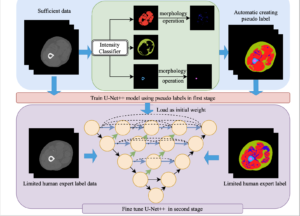
Purpose: Muscle, bone, and fat segmentation from thigh images is essential for quantifying body composition. Voxelwise image segmentation enables quantification of tissue properties including area, intensity, and texture. Deep learning approaches have had substantial success in medical image segmentation, but they typically require a significant amount of data. Due to the high cost of manual annotation, training deep learning models with limited human label data is desirable, but it is a challenging problem.
Approach: Inspired by transfer learning, we proposed a two-stage deep learning pipeline to address the thigh and lower leg segmentation issue. We studied three datasets, 3022 thigh slices and 8939 lower leg slices from the BLSA dataset and 121 thigh slices from the GESTALT study. First, we generated pseudolabels for thigh based on approximate handcrafted approaches using CT intensity and anatomical morphology. Then, those pseudolabels were fed into deep neural networks to train models from scratch. Finally, the first stage model was loaded as the initial- ization and fine-tuned with a more limited set of expert human labels of the thigh.
Results: We evaluated the performance of this framework on 73 thigh CT images and obtained an average Dice similarity coefficient (DSC) of 0.927 across muscle, internal bone, cortical bone, subcutaneous fat, and intermuscular fat. To test the generalizability of the proposed framework, we applied the model on lower leg images and obtained an average DSC of 0.823.
Conclusions: Approximated handcrafted pseudolabels can build a good initialization for deep neural networks, which can help to reduce the need for, and make full use of, human expert labeled data.