Batch size: go big or go home? Counterintuitive improvement in medical autoencoders with smaller batch size
Cailey I. Kerley*, Leon Y. Cai*, Yucheng Tang, Lori L. Beason-Held, Susan M. Resnick, Laurie E. Cutting, and Bennett A. Landman.
*Equal first authorship
Abstract
Batch size is a key hyperparameter in training deep learning models. Conventional wisdom suggests larger batches produce improved model performance. Here we present evidence to the contrary, particularly when using autoencoders to derive meaningful latent spaces from data with spatially global similarities and local differences, such as electronic health records (EHR) and medical imaging. We investigate batch size effects in both EHR data from the Baltimore Longitudinal Study of Aging and medical imaging data from the multimodal brain tumor segmentation (BraTS) challenge. We train fully connected and convolutional autoencoders to compress the EHR and imaging input spaces, respectively, into 32-dimensional latent spaces via reconstruction losses for various batch sizes between 1 and 100. Under the same hyperparameter configurations, smaller batches improve loss performance for both datasets. Additionally, latent spaces derived by autoencoders with smaller batches capture more biologically meaningful information. Qualitatively, we visualize 2-dimensional projections of the latent spaces and find that with smaller batches the EHR network better separates the sex of the individuals, and the imaging network better captures the right-left laterality of tumors. Quantitatively, the analogous sex classification and laterality regressions using the latent spaces demonstrate statistically significant improvements in performance at smaller batch sizes. Finally, we find improved individual variation locally in visualizations of representative data reconstructions at lower batch sizes. Taken together, these results suggest that smaller batch sizes should be considered when designing autoencoders to extract meaningful latent spaces among EHR and medical imaging data driven by global similarities and local variation.
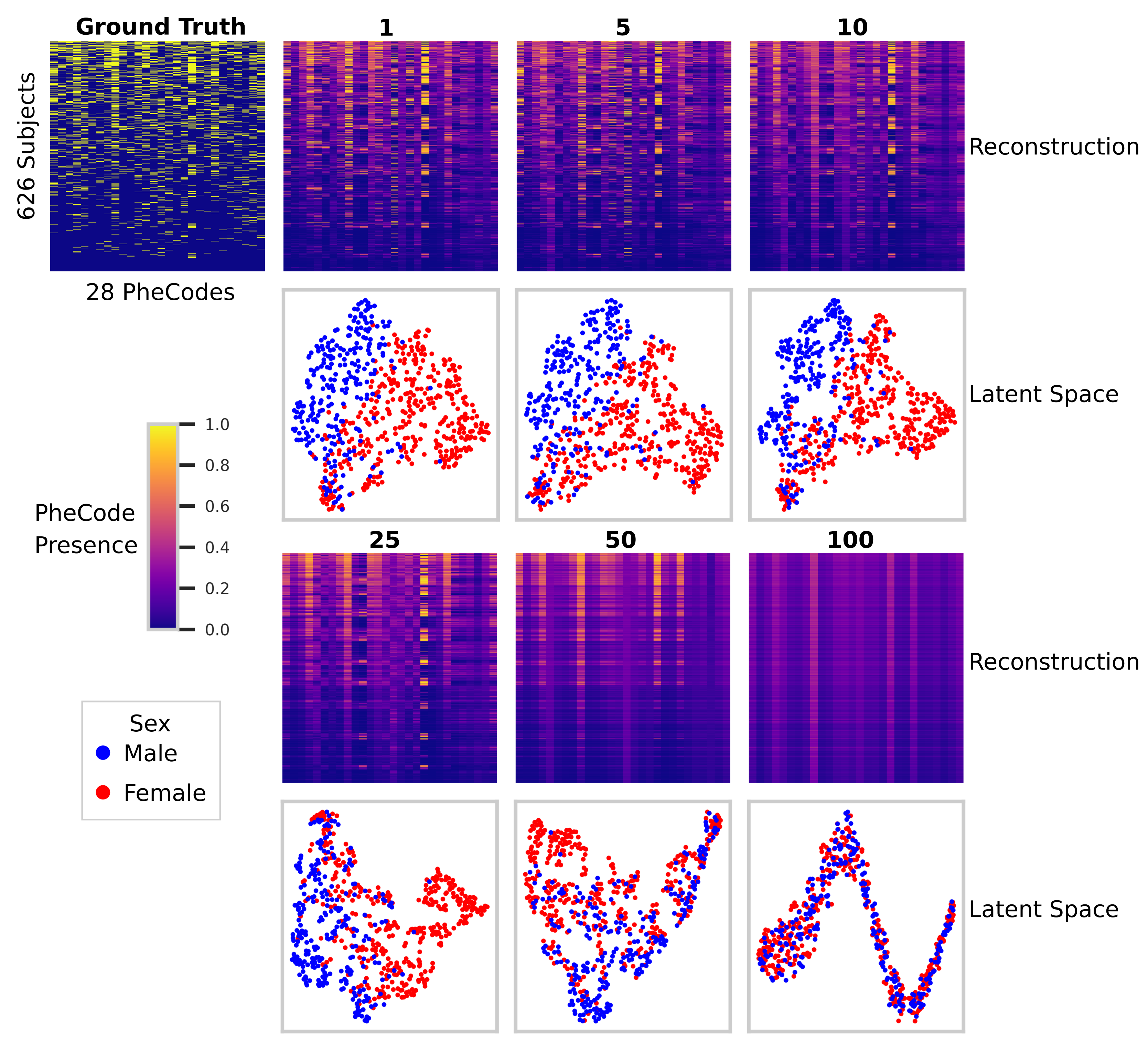
Figure 3. EHR autoencoder ground truth, reconstruction, and latent space visualizations for the withheld test set (n = 626) across six batch sizes (1, 5, 10, 25, 50, and 100). The ground truth and reconstructions consisted of a 626 x 28 grid, with individuals on the y-axis and the 28 most representative PheCodes on the x-axis; individuals were sorted so that those with the most PheCode events are at the top of the grid. The reconstructed PheCode value was indicated via color; note that while the ground truth contained only binary values, reconstructions were the output of a sigmoid function and therefore contained intermediate values. Latent space visualizations consisted of a 2-dimensional tSNE projection of the 32-dimensional latent space embeddings of the test cohort; color in this visualization denoted individual sex.