Deep Learning Category
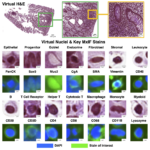
Nucleus subtype classification using inter-modality learning
Dec. 19, 2023—Lucas W. Remedios, Shunxing Bao, Samuel W. Remedios, Ho Hin Lee, Leon Y. Cai, Thomas Li, Ruining Deng, Can Cui, Jia Li, Qi Liu, Ken S. Lau, Joseph T. Roland, Mary K. Washington, Lori A. Coburn, Keith T. Wilson, Yuankai Huo, Bennett A. Landman (2024). Nucleus subtype classification using inter-modality learning. SPIE Medical Imaging 2024 :...
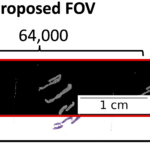
Exploring shared memory architectures for end-to-end gigapixel deep learning
Dec. 19, 2023—Lucas W. Remedios, Leon Y. Cai, Samuel W. Remedios, Karthik Ramadass, Aravind Krishnan, Ruining Deng, Can Cui, Shunxing Bao, Lori A. Coburn, Yuankai Huo, Bennett A. Landman (2023). Exploring shared memory architectures for end-to-end gigapixel deep learning. MIDL 2023 short paper track Full text: NIHMSID Abstract Deep learning has made great strides in medical imaging, enabled by hardware advances in GPUs. One major constraint for the development...
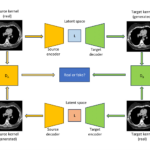
Inter-vendor harmonization of CT reconstruction kernels using unpaired image translation
Dec. 1, 2023—Aravind R. Krishnan, Kaiwen Xu, Thomas Li, Chenyu Gao, Lucas W. Remedios, Praitayini Kanakaraj, Ho Hin Lee, Shunxing Bao, Kim L. Sandler, Fabien Maldonado, Ivana Išgum, and Bennett A. Landman “Inter-vendor harmonization of CT reconstruction kernels using unpaired image translation”, Proc. SPIE 12926, Medical Imaging 2024: Image Processing, 129261D (2 April 2024); https://doi.org/10.1117/12.3006608 Abstract The reconstruction kernel in computed tomography (CT) generation determines the texture of the image. Consistency...
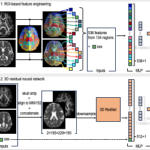
Predicting Age from White Matter Diffusivity with Residual Learning
Dec. 1, 2023—Chenyu Gao, Michael E. Kim, Ho Hin Lee, Qi Yang, Nazirah Mohd Khairi, Praitayini Kanakaraj, Nancy R. Newlin, Derek B. Archer, Angela L. Jefferson, Warren D. Taylor, Brian D. Boyd, Lori L. Beason-Held, Susan M. Resnick, The BIOCARD Study Team, Yuankai Huo, Katherine D. Van Schaik, Kurt G. Schilling, Daniel Moyer, Ivana Išgum, Bennett A....
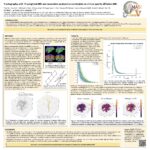
Tractography with T1-weighted MRI and associated anatomical constraints on clinical quality diffusion MRI
Dec. 1, 2023—Tian Yu, Yunhe Li, Michael E. Kim, Chenyu Gao, Qi Yang, Leon Y. Cai, Susane M. Resnick, Lori L. Beason-Held, Daniel C. Moyer, Kurt G. Schilling, Bennett A. Landman, “Tractography with T1-weighted MRI and associated anatomical constraints on clinical quality diffusion MRI”, SPIE Medical Imaging 2024 Full text: NIHMSID Abstract Diffusion MRI (dMRI) streamline tractography, the...
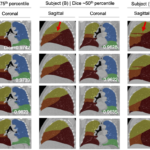
Quantifying emphysema in lung screening computed tomography with robust automated lobe segmentation
Sep. 1, 2023—Thomas Z. Li, Ho Hin Lee, Kaiwen Xu, Riqiang Gao, Benoit M. Dawant, Fabien Maldonado, Kim L. Sandler, Bennett A. Landman. Journal of Medical Imaging 10(4), 044002 (2023), doi: 10.1117/1.JMI.10.4.044002. Full Text Abstract Introduction: Anatomy-based quantification of emphysema in a lung screening cohort has the potential to improve lung cancer risk stratification and risk communication....
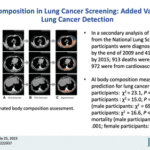
AI Body Composition in Lung Cancer Screening: Added Value Beyond Lung Cancer Detection
Aug. 31, 2023—Kaiwen Xu, Mirza S. Khan, Thomas Z. Li, Riqiang Gao, James G. Terry, Yuankai Huo, Thomas A. Lasko, John Jeffrey Carr, Fabien Maldonado, Bennett A. Landman, Kim L. Sandler Paper: https://pubs.rsna.org/doi/epdf/10.1148/radiol.222937 Abstract Background An artificial intelligence (AI) algorithm has been developed for fully automated body composition assessment of lung cancer screening noncontrast low-dose CT of the...
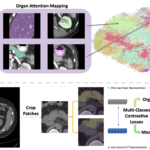
Semantic-Aware Contrastive Learning for Multi-object Medical Image Segmentation
Aug. 31, 2023—Ho Hin Lee, Yucheng Tang, Qi Yang, Xin Yu, Leon Y. Cai, Lucas W. Remedios, Shunxing Bao, Bennett A. Landman, Yuankai Huo Paper: https://ieeexplore.ieee.org/document/10149329 Code: https://github.com/MASILab/DCC_CL Abstract Medical image segmentation, or computing voxel-wise semantic masks, is a fundamental yet challenging task in medical imaging domain. To increase the ability of encoder-decoder neural networks to perform this task...
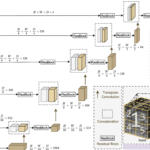
UNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Aug. 31, 2023—Xin Yu, Qi Yang, Yinchi Zhou, Leon Y. Cai , Riqiang Gao, Ho Hin Lee, Thomas Li, Shunxing Bao, Zhoubing Xu, Thomas A. Lasko, Richard G. Abramson, Zizhao Zhang, Yuankai Huo, Bennett A. Landman, Yucheng Tang Paper: https://arxiv.org/abs/2209.14378 Code: https://github.com/Project-MONAI/model-zoo/tree/dev/models Abstract Transformer-based models, capable of learning better global dependencies, have recently demonstrated exceptional repre- sentation learning capabilities...
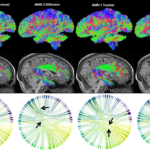
Convolutional-recurrent neural networks approximate diffusion tractography from T1-weighted MRI and associated anatomical context
May. 29, 2023—Leon Y. Cai, Ho Hin Lee, Nancy R. Newlin, Cailey I. Kerley, Praitayini Kanakaraj, Qi Yang, Graham W. Johnson, Daniel Moyer, Kurt G. Schilling, François Rheault, and Bennett A. Landman Paper: https://www.biorxiv.org/content/10.1101/2023.02.25.530046v2 Code: https://github.com/MASILab/cornn_tractography Abstract Diffusion MRI (dMRI) streamline tractography is the gold-standard for in vivo estimation of white matter (WM) pathways in the brain. However, the...